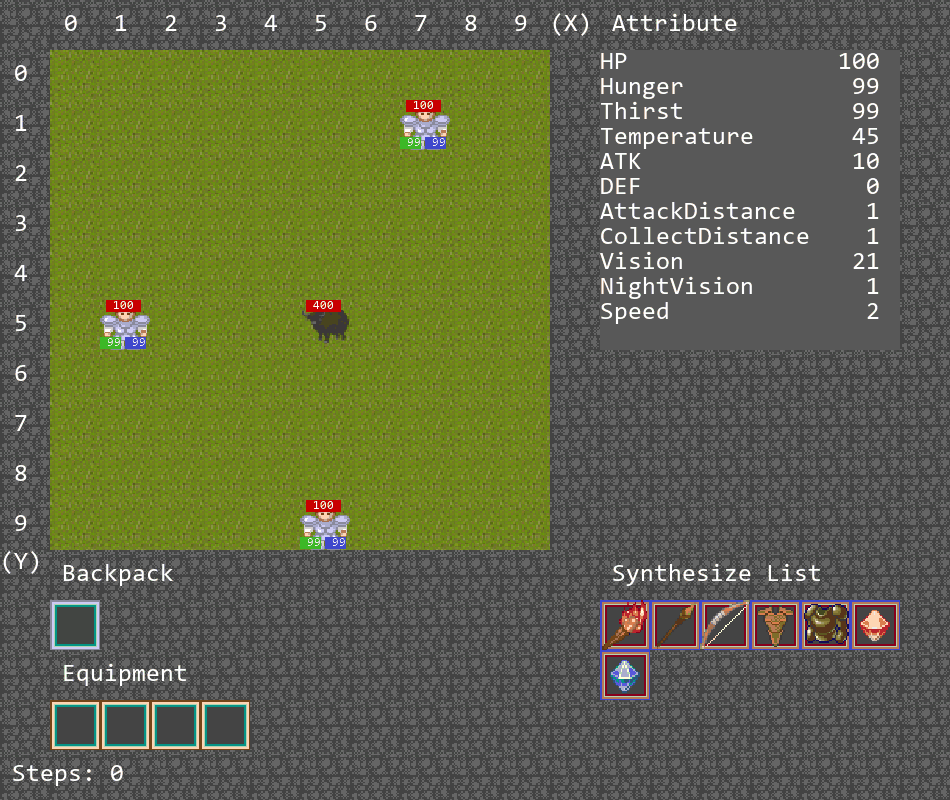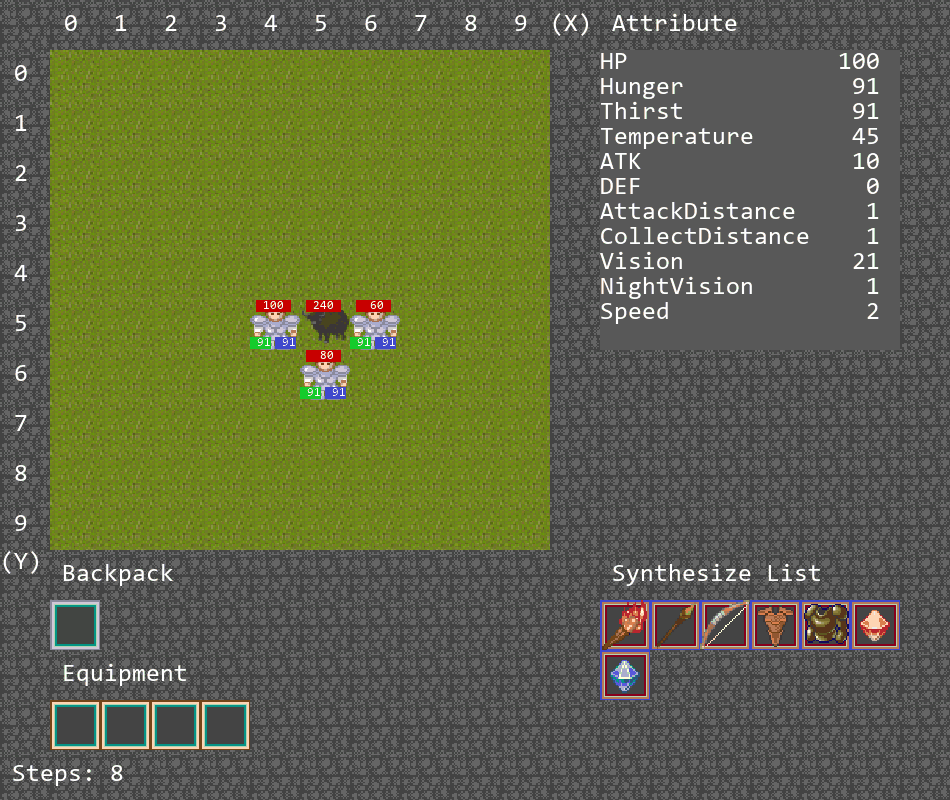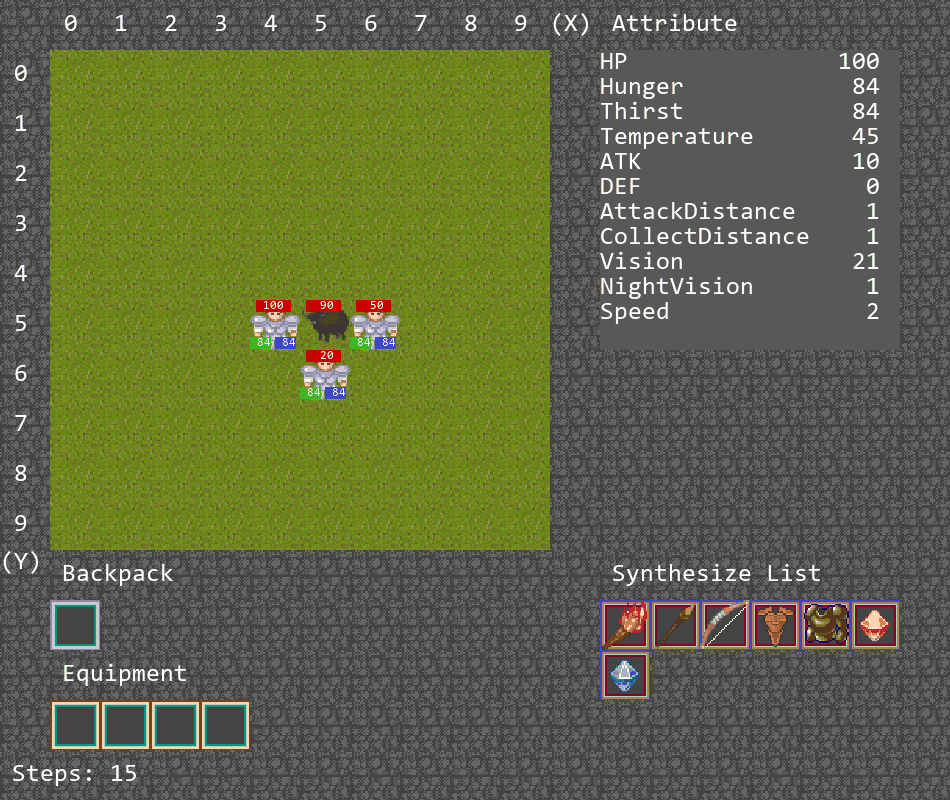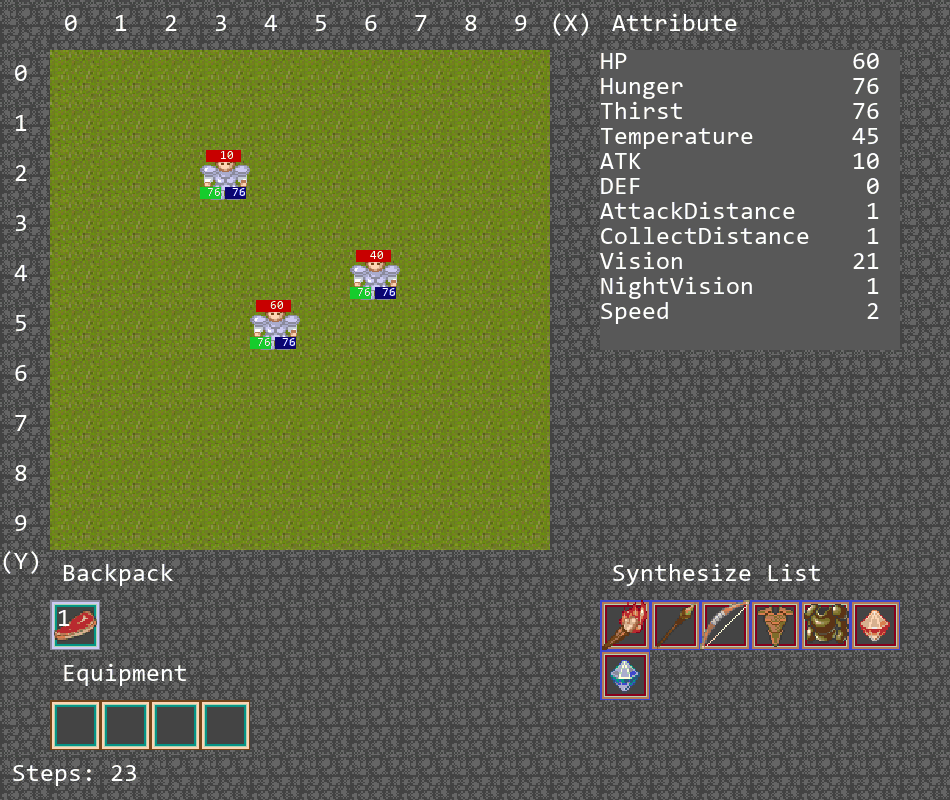
多智能体游戏
概述
- 本示例主要展示如何修改初始化文件配置中的csv文件配置多智能体游戏。
- 本示例展示了两个demo游戏:合作生存和合作捕猎。
具体设计
合作生存游戏
环境主要是为了训练多智能体ai算法的合作能力,设置地图大小为10 * 10,其中的主要资源是猪,能够获得肉满足agent的消耗,补充饱食度。其中有两种agent,其中一种agent负责供养另外一种agent,被供养的agent死亡时,游戏结束。
环境设计
环境设计如下。地图大小10x10,设定白天长度和一天长度相同,agent数量为4。
| 地图属性 | 值 |
|---|---|
| MapSizeX | 10 |
| MapSizeY | 10 |
| DaytimeLength | 200 |
| DayLength | 200 |
| AgentCount | 4 |
| NA | 1 |
| A | 3 |
agent设计
agent分为两种类型,第一种agent不能进行攻击,不能够从猪获得肉资源,第二种agent可以无限存活,并且可以进行攻击。只有在第二种agent击杀猪后第一种agent才有获得肉的机会。
配置Agent如下所示
| agent类型 | 饥饿 | 攻击力 | 拾取距离 | 攻击距离 | 视野 | 移速 |
|---|---|---|---|---|---|---|
| NA | 100 | - | 2 | 2 | (全图) | 2 |
| A | 999 | 10 | 2 | 2 | (全图) | 2 |
动植物设计
环境中有10只猪,每只猪有10点生命值,死后掉落为3个肉,每个肉能补充20点饱食度,极限能够提供的饱食度为100 + 3 * 10 * 20 = 700点饱食度
| 猪的属性 | 血量 | 攻击力 | 防御力 | 攻击距离 | 移速 |
|---|---|---|---|---|---|
| 数值 | 10 | 0 | 0 | 0 | 1 |
通过设置DropTable一项为Meat:3,表示Pig被击杀后掉落3个meat
通过设置Distribution一项为Grassland:10,表示在grassland随机生成10个Pig
通过设置Temper一项为0,猪见到agent以后会使用自带的逃跑策略远离agent
游戏规则设计
agent可以进行移动,攻击,消耗等动作,不同种类的agent要合理合作,保证NA类型的agent存活尽可能长的时间。
可视化运行Demo
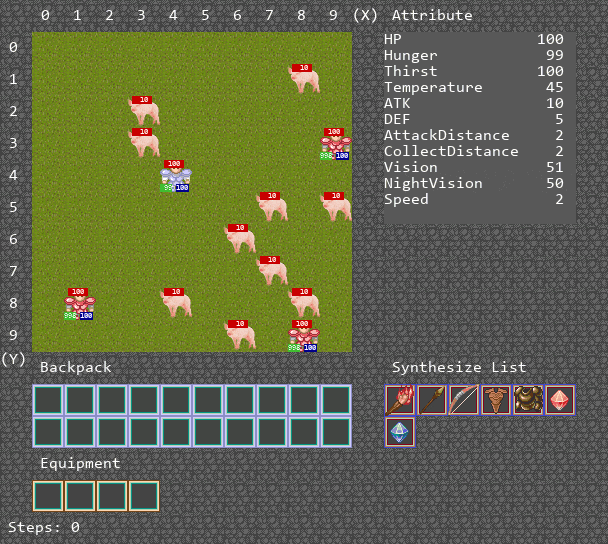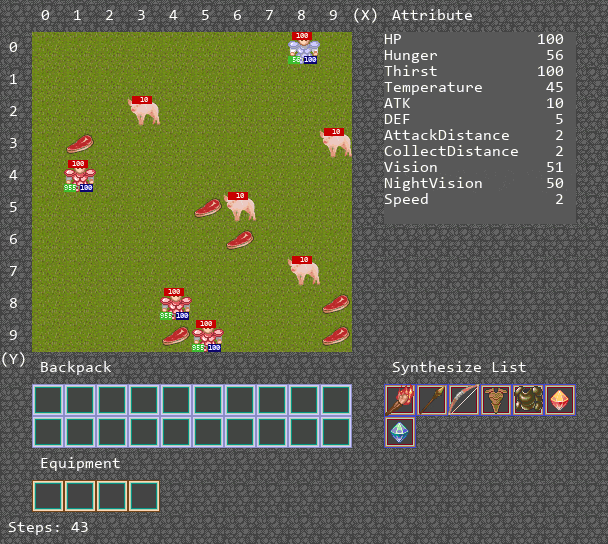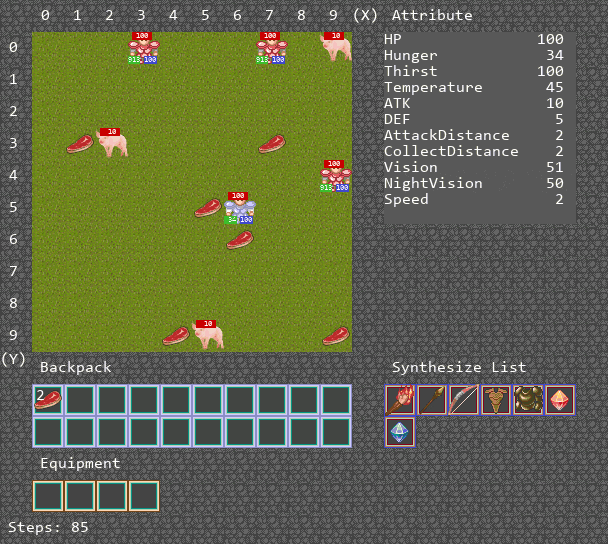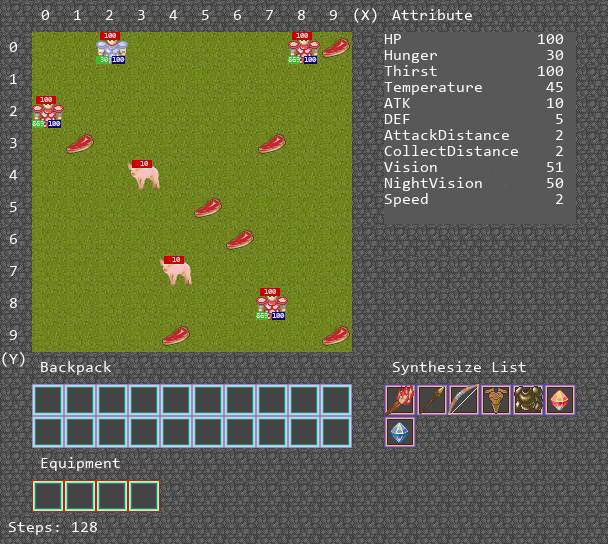
算法运行Demo
编写gym wrapper实现观测空间、动作空间裁剪,与算法对接:
(1)observation包含:原始obs,包括agent坐标,属性,能观测到的地图信息,背包信息。
(2)action为一维离散值,范围是0 ~ 13,0 ~12表示范围2以内的坐标格子。13表示消耗。当选定坐标格以后,根据坐标上的物品进行动作,由于坐标上的物品类型是互斥的,因此动作也是互斥的,并不会造成自由度下降。
reward设计为:
(1)攻击猪的reward为2,杀死猪的reward为4
(2)当agentNA死亡时,所有agent获得-10的reward,游戏结束
(3)当agent捡起meat时,reward为4
(4)当agent消耗肉时,检查获得的饥饿度增益是否大于18,大于18时,增加等同于饥饿度增量的奖励。无论是否大于18,都获得(20-饥饿度增量)的惩罚,这代表溢出所浪费的饥饿度。
训练过程为:
(1)固定种子生成地图,然后让agent进行训练,总共训练了大约1M步
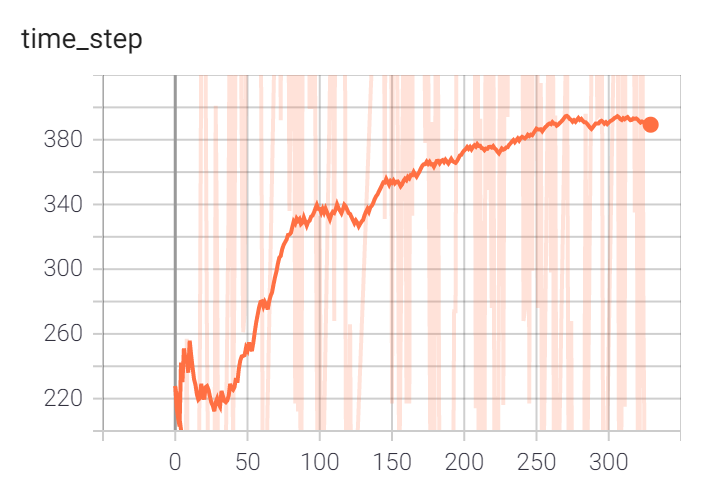
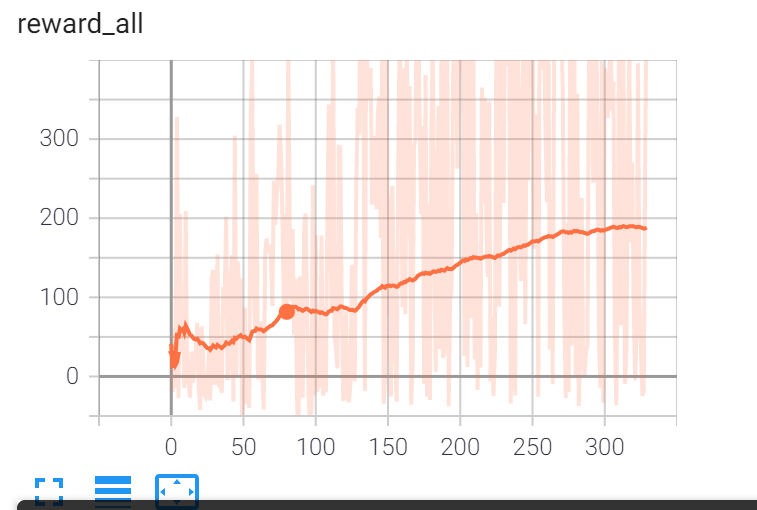
(2)随机种子生成地图,然后让agent进行训练,总共训练了300episode,但是这时由于之前训练过,一个episode大约有400步,所以大约相当于150k步(step与reward曲线如下)
算法运行demo:
合作捕猎游戏
此游戏将在地图中生成3个agent和一头牛,由于牛会对agent进行反击,需要3个agent合力将牛击杀,并将掉落的一块肉捡起,以此完成游戏。
环境设计
配置general.csv如下。地图大小10x10,设定白天长度和一天长度相同,因此没有夜晚。由于有3个agent,因此也将agentCount设为3。
| 地图属性 | 值 |
|---|---|
| MapSizeX | 10 |
| MapSizeY | 10 |
| DaytimeLength | 200 |
| DayLength | 200 |
| AgentCount | 3 |
配置landform.csv如下。只设置了一项,因此地形只有草原。
| 地形 | 比例 |
|---|---|
| Grassland | (any) |
将resource.csv中清空,让环境中不生成其他资源
agent设计
配置Agent.csv如下所示
| agent属性 | 血量 | 攻击力 | 防御力 | 攻击距离 | 视野 | 移速 |
|---|---|---|---|---|---|---|
| 数值 | 100 | 10 | 0 | 1 | 20(全图) | 2 |
通过设置actable一项为'm : a : p',只允许进行move、attack、pickup三个动作
通过设置Distribution一项为'Grassland:3',表示在grassland随机生成3个该agent
动植物设计
配置being.csv如下所示
| 牛的属性 | 血量 | 攻击力 | 防御力 | 攻击距离 | 移速 |
|---|---|---|---|---|---|
| 数值 | 400 | 10 | 0 | 1 | 2 |
通过设置DropTable一项为Meat:1,表示牛被击杀后掉落1个meat
通过设置Distribution一项为Grassland:1,表示在grassland随机生成1个Ox
通过设置Temper一项为1,表示牛受到攻击后会进行反击,反击的伤害根据牛的攻击力和agent的防御力计算,因此agent无法单独击倒牛
游戏规则设计
通过设置game_done.json,使得如果某个agent的属性值(血量、饱食度、口渴度)降至0或者捡到肉后,该agent的done=True
| 类别 | 属性 | 判断值 |
|---|---|---|
| attrbute | Hunger or Thirst, HP | 0 |
| backpack | Meat | 1 |
可视化运行Demo
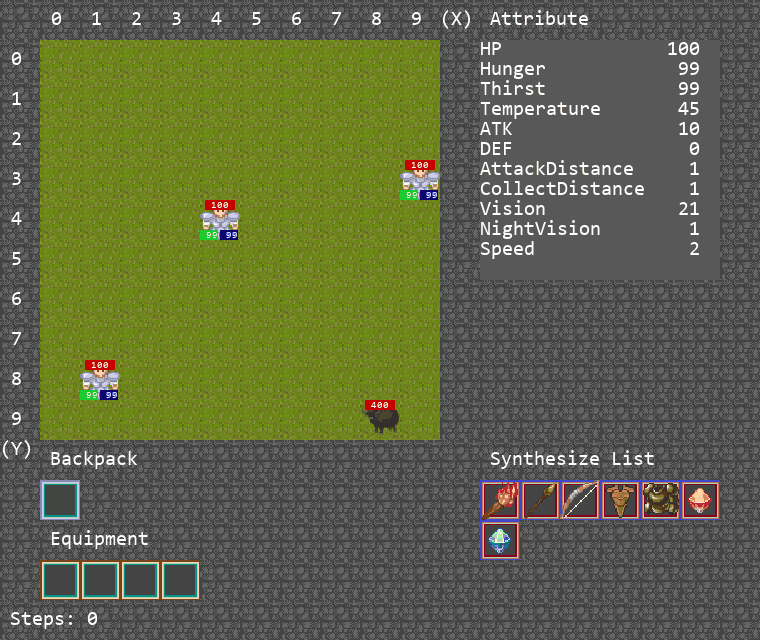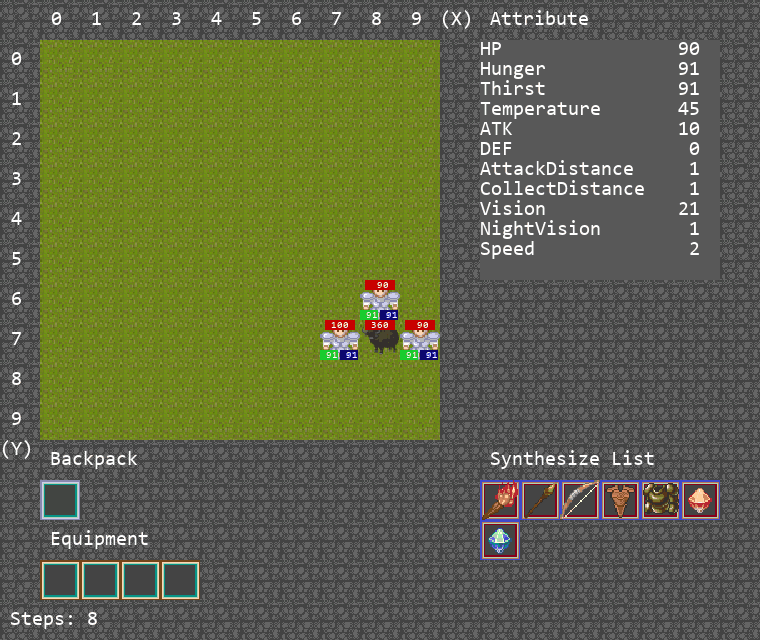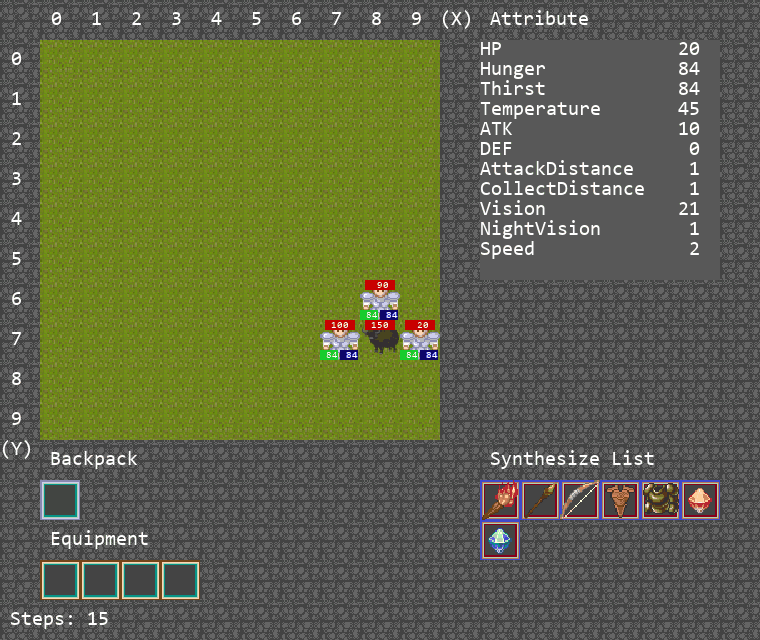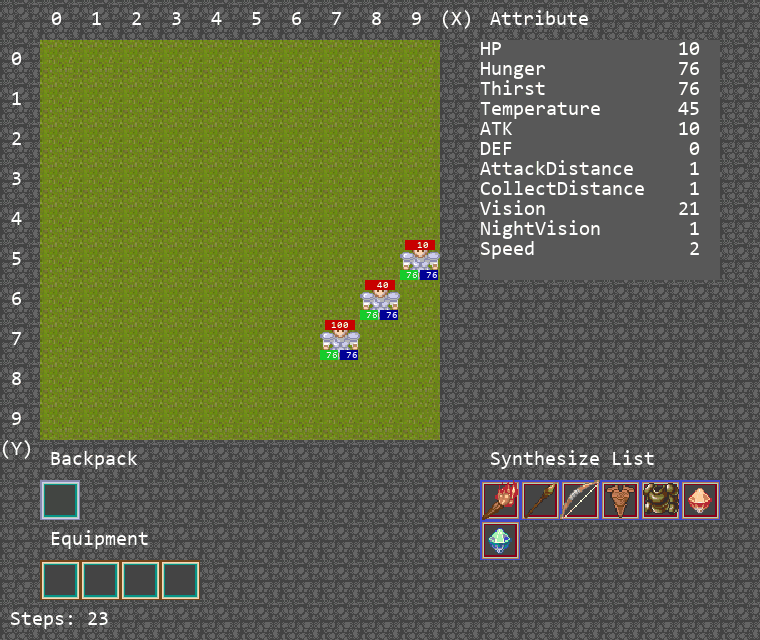
算法运行Demo
编写gym wrapper实现观测空间、动作空间裁剪,与算法对接:
(1)observation包含:自身位置、自身血量、背包、其他agent位置、牛的位置、掉落的肉的位置
(2)action为一维离散值,范围是0 ~ 19,0 ~3表示向四个方向攻击、4 ~ 7表示拾取、 8~19表示移动(移动速度为2,可能的选择有12个位置)
reward设计为:
(1)攻击牛的reward为2,杀死牛的reward为5
(2)按照距离牛的远近附加一个负的reward,值为-0.1*Distance
(3)有agent被牛击杀时,所有agent获得-10的reward,游戏结束
(4)当agent捡起肉,游戏结束,捡起肉的agent给20reward,其他agent的reward为5
训练过程为:
(1)使用multi-agent dqn在牛的血量为200,攻击力为5的环境下训练约200k step(下图中的橙线)
(2)接着在牛的血量为400,攻击力为5下再训练了约200k step(下图中的蓝线,有重新探索的过程)。

算法运行结果如下,此时牛的数值为原本设计中的血量400,攻击力10,能够完成合力击杀牛的任务,不过存在泛化能力不足的问题。