合成游戏
概述
- 本示例主要展示如何修改初始化文件配置中的4_item.csv文件构造一个复杂的合成游戏。
- 该游戏的最终目标是合成FancyColorDiamond,具有很长的合成表的合成路径。
具体设计
动植物设计
目前环境中配备了10个being,具体信息可见config/3_being.csv,下面给出它们的主要信息:
| 名称 | 介绍 | 掉落 | 需求 |
|---|---|---|---|
| Pig | 猪 | 击杀掉落Leather、Meat、Tendon | StoneSword及以上 |
| Rabbit | 兔子 | 击杀掉落Meat | WoodSword及以上 |
| Ox | 公牛 | 击杀掉落Meat | IronSword及以上 |
| Goat | 羊 | 击杀掉落Meat | WoodSword及以上 |
| Tree | 树 | 可以采集Branch,击杀额外掉落Wood | attack 需要equip任意Axe |
| AppleTree | 苹果树 | 可以采集Apple,击杀额外掉落Wood | attack 需要equip任意Axe |
| Grass | 草 | 采集和击杀掉落Cutgrass | equip任意具有攻击力装备 |
| Rock | 石头 | 可以采集Stone,击杀额外掉落Stone | attack 需要equip任意Pickaxe |
| IronMine | 铁矿 | 击杀掉落IronOre | StonePickaxe及以上 |
| GemMine | 宝石矿 | 击杀掉落GemStone | SteelPickaxe及以上 |
游戏机制为受到的伤害=攻击者攻击力-被攻击者防御力,攻击being时,不产生效果的原因既可能为没有装备对应的装备,也可能是攻击力小于目标的防御力。
合成表设计
| 名称 | 描述 | 合成表 | 合成需求 |
|---|---|---|---|
| StoneSmelter | smelter,提供Smelter_A类buff | Stone:8 | |
| IronSmelter | smelter,提供Smelter_AA类buff | IronIngot:8 | Smelter_A类及以上buff |
| SteelSmelter | smelter,提供Smelter_AAA类buff | SteelIngot:8 | Smelter_AA类及以上buff |
| Spear | Weapon,增加攻击力和攻击距离 | Branch:1;Cutgrass:2;Stone:1 | |
| Bow | Weapon,增加攻击力和攻击距离 | Branch:2;Cutgrass:2;Tendon:1 | |
| LeatherArmor | Armor,增加防御力 | Leather:2;Cutgrass:4 | |
| WoodArmor | Armor,增加防御力 | Wood:2;Cutgrass:4 | |
| WarmStone | Other,增加体温 | Stone:5;Cutgrass:5;Torch:1 | |
| ColdStone | Other,降低体温 | Stone:5;Cutgrass:6;Ice:4 | |
| Coal | 碳 | Wood:2 | |
| IronIngot | 铁 | IronOre:1;Coal:1 | Smelter_A类及以上buff |
| SteelIngot | 钢 | IronIngot:1;Coal:2 | Smelter_AA类及以上buff |
| WoodAxe | Weapon,加攻击力,可砍树 | Branch:3 | |
| WoodPickaxe | Weapon,加攻击力,可采矿石 | Branch:4 | |
| WoodSword | Weapon,增加攻击力和攻击范围 | Branch:3 | |
| StoneAxe | Weapon,加攻击力,可砍树 | Wood:2;Stone:2 | |
| StonePickaxe | Weapon,加攻击力,可采矿石 | Wood:2;Stone:3 | |
| StoneSword | Weapon,增加攻击力和攻击范围 | Wood:1;Stone:2 | |
| IronAxe | Weapon,加攻击力,可砍树 | Wood:2;IronIngot:2 | Smelter_AA类及以上buff |
| IronPickaxe | Weapon,加攻击力,可采矿石 | Wood:2;IronIngot:3 | Smelter_AA类及以上buff |
| IronSword | Weapon,增加攻击力和攻击范围 | Wood:1;IronIngot:2 | Smelter_AA类及以上buff |
| SteelAxe | Weapon,加攻击力,可砍树 | Wood:2;Steel:2 | Smelter_AAA类及以上buff |
| SteelPickaxe | Weapon,加攻击力,可采矿石 | Wood:2;Steel:3 | Smelter_AAA类及以上buff |
| SteelSword | Weapon,增加攻击力和攻击范围 | Wood:1;Steel:2 | Smelter_AAA类及以上buff |
| Diamond | 钻石 | Coal:4 | Smelter_AAA类及以上buff |
| Zircon | 锆英石 | GemStone:2;IronMine:4 | Smelter_AAA类及以上buff |
| Peridot | 橄榄石 | GemStone:3;IronMine:3 | Smelter_AAA类及以上buff |
| Tanzanite | 坦桑石 | GemStone:6 | Smelter_AAA类及以上buff |
| Spinel | 尖晶石 | IronMine:6 | Smelter_AAA类及以上buff |
| Kunzite | 锂辉石 | GemStone:4;IronMine:2 | Smelter_AAA类及以上buff |
| Citrine | 黄宝石 | Zircon:1;Diamond:1 | Smelter_AAA类及以上buff |
| Emerald | 绿宝石 | Peridot:1;Diamond:1 | Smelter_AAA类及以上buff |
| Saphire | 蓝宝石 | Tanzanite:1;Diamond:1 | Smelter_AAA类及以上buff |
| Ruby | 红宝石 | Spinel:1;Diamond:1 | Smelter_AAA类及以上buff |
| Amethyst | 紫宝石 | Kunzite:1;Diamond:1 | Smelter_AAA类及以上buff |
| FancyColorDiamond | 彩钻 | Citrine:1;Emerald:1; Sapphire:1;Rubi:1;Amethyst:1 | Smelter_AAA类及以上buff |
玩法策略设计
在合成游戏中,玩家的最终目标是获得彩钻,即FancyColorDiamond。为了达成这一目的,玩家需要在保证自己生存的同时收集材料、升级装备,最终通过多步合成获取。
以下为在默认配置下,快速获取彩钻的方式。当然,使用者可以根据自身需要,调整config文件夹下的配置信息,来增加或者降低游戏难度。如,若增加苹果树的重生周期和生产周期,则会迫使agent需要在游戏中期合成部分装备去杀死动物保证生存,就给予了Agent更大的生存压力。
保证生存
在默认配置中,AppleTree的重生周期比较快,因此玩家只需要定期的砍AppleTree、捡取Apple,在需要时consume就能保证饱食度。饥渴度通过采集Pool中的Water保证,在移动时看见新的Pool可以去采集,保证Water和Apple都有50+基本就足够了。
合成装备
在合成游戏下,采集/合成物品有时需要身上的buff满足特定条件(Condition)。在目前配置下,获得彩钻的过程中需要的buff都是由装备提供的,在保证生存的情况下,获得这些装备可以参考如下步骤:
- 捡Branch,用Branch合成WoodAxe并装备,不断砍树获得Wood和Branch,当然顺带也可能获得Apple;
- 捡Stone,用Wood和Stone合成StonePickaxe并装备,不断挖IronMine和StoneMine获得Stone和IronOre;
- 用Stone合成StoneSmelter并装备;
- 用Wood合成Coal,用Coal和IronOre合成IronIngot;
- 用IronIngot合成IronSmelter并装备;
- 用Coal和IronIngot合成SteelIngot;
- 用SteelIngot合成SteelSmelter并装备;
- 用SteelIngot和Wood合成SteelPickaxe并装备;
- 开始挖GemMine获得GemStone;
- 上述所有Item准备充足,即通过合成表一步一步合成获取彩钻即可。
可视化运行Demo
合成游戏的运行Demo如下图中所示,由于合成到FancyColorDiamond所需要的步骤过多,只显示智能体合成到StoneSword。
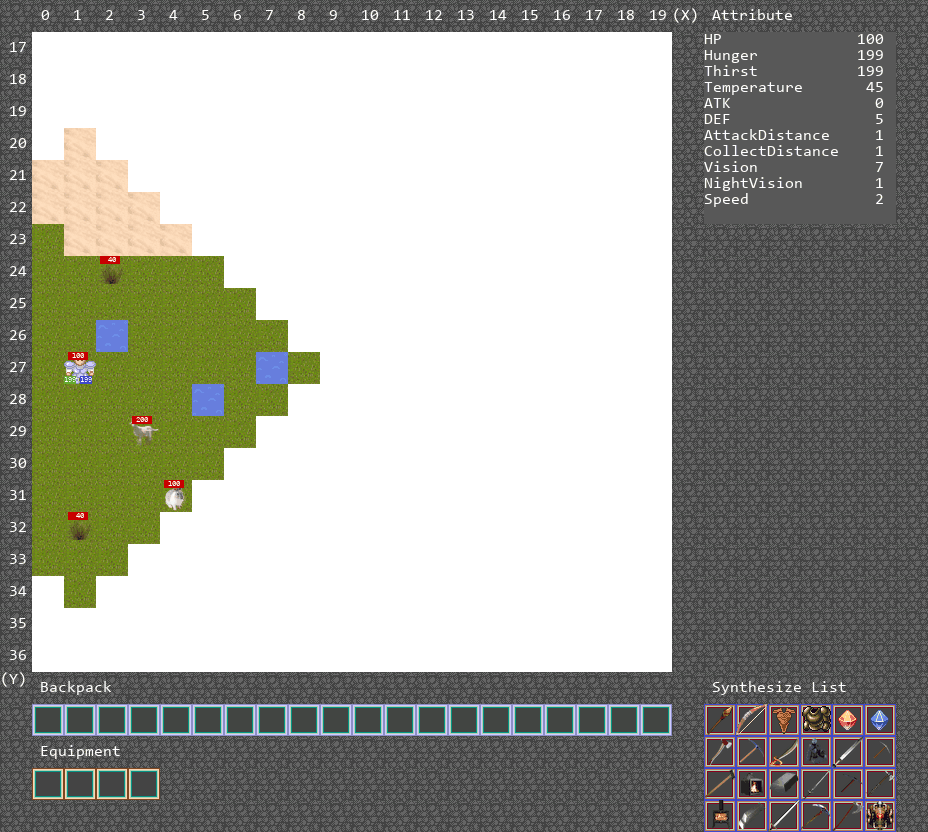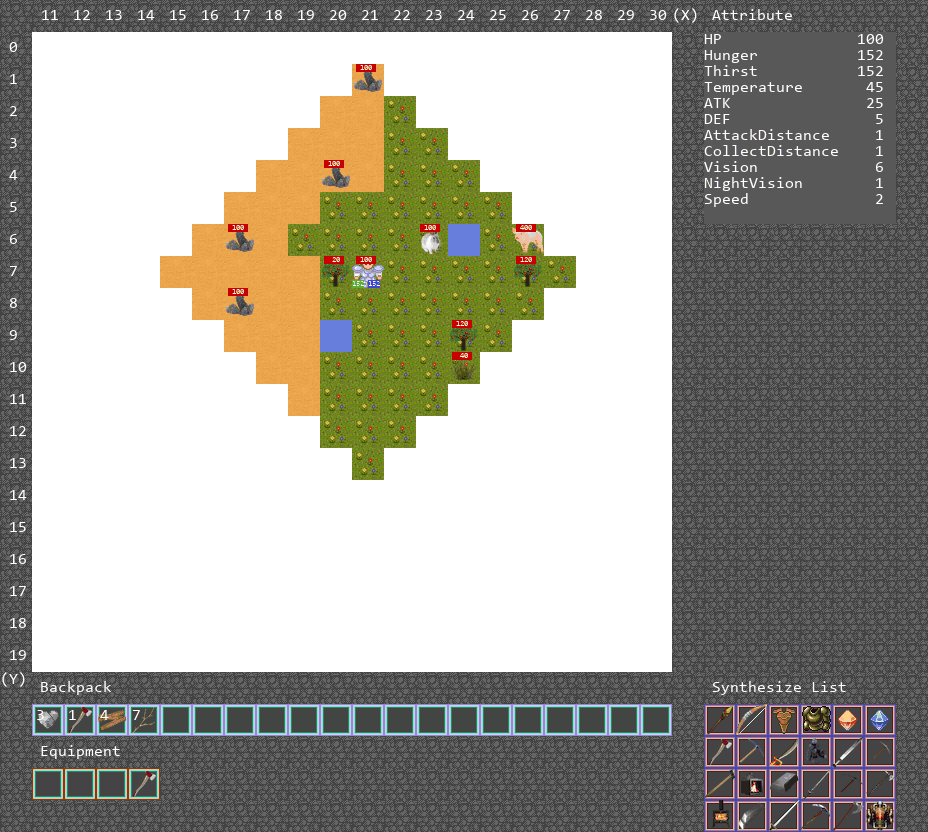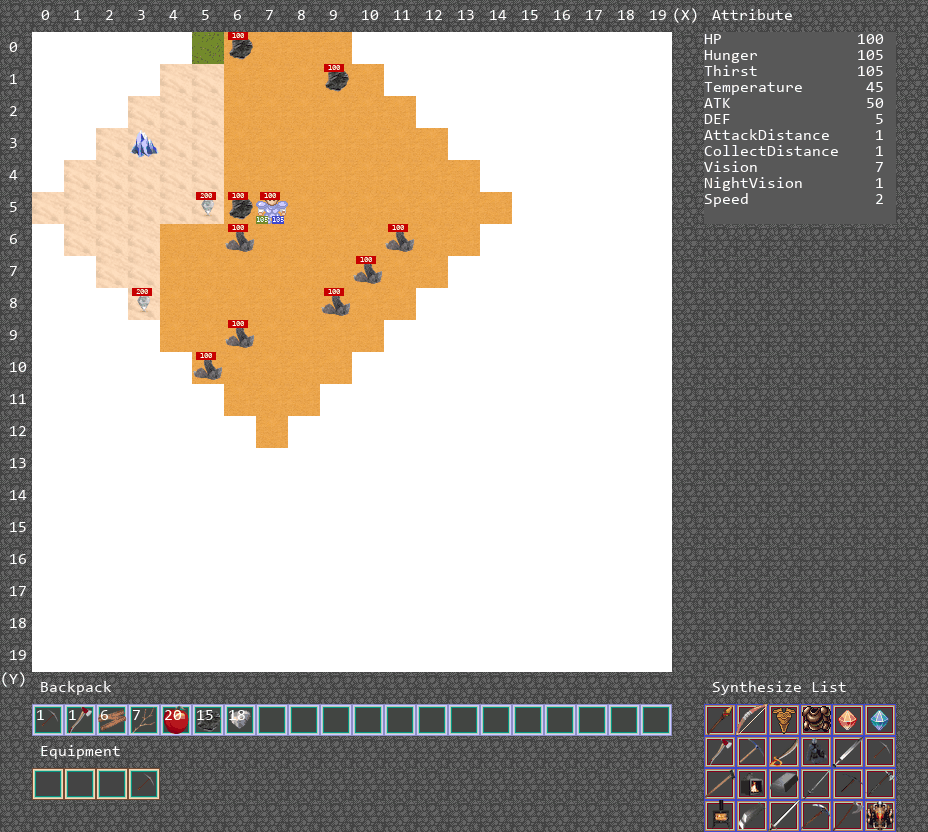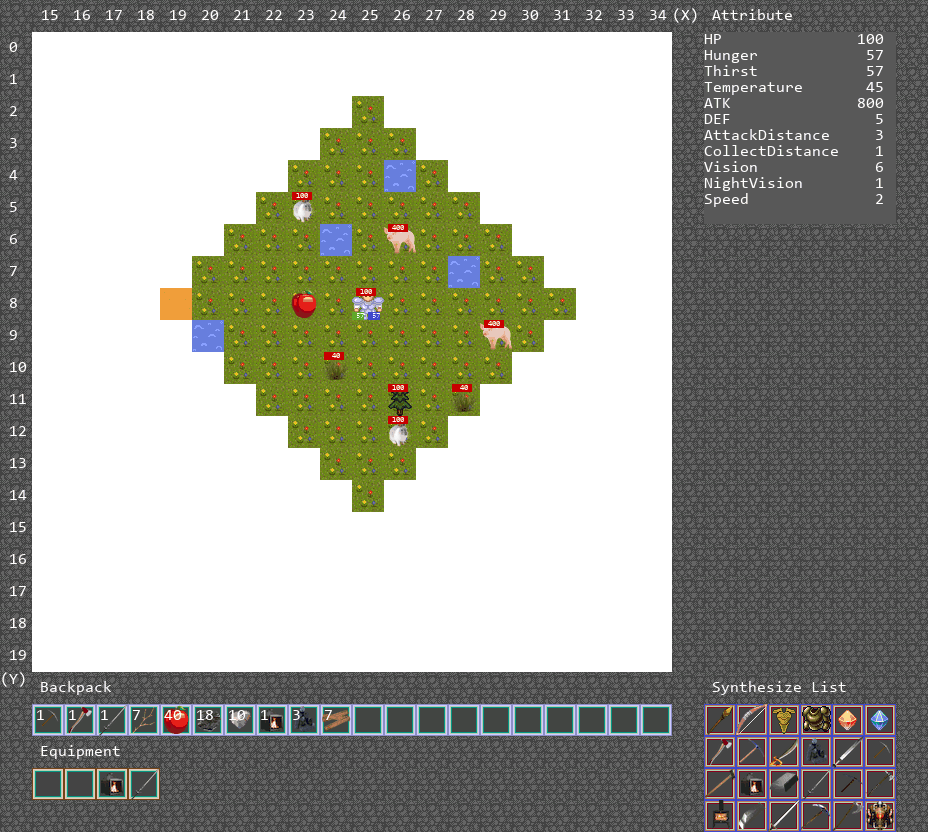
算法运行Demo
训练方法
算法既可以在原始动作空间上训练,也可以在简化后的动作空间上训练。下面展示如何在原始动作空间上使用stable_baselines3库中的PPO算法进行训练。
import gym, eden
import time
from eden.wrappers import SelectActionTarget, ObsScale, Reward,ObsReader,ActScale
from stable_baselines3 import PPO
from eden.wrappers.one_agent_wrapper import OneAgent
import tensorboard
from eden.interactive import Render
if __name__ == '__main__':
e = gym.make('eden-v1')
e.reset()
e = Reward(e)#reward函数
e = OneAgent(e)#将多智能体环境变为单智能体环境
#e = ObsReader(e)#解析observation的wrapper,若想使用原始obs可删掉
#e = ActScale(e)#简化动作空间的wrapper,若想采用原始动作空间删除这行即可
e.reset()
tensorboard_dir = "PPO_compound_test"
model = PPO("MlpPolicy", e, verbose=1,tensorboard_log=tensorboard_dir + '/')
model.learn(total_timesteps=1000000)
model.save("ppo_test")#保存文件位置
#以下为观察模型效果的代码,可以展示游戏界面
#render = Render(e,10)
#model = PPO.load("ppo_test")
#obs = e.reset()
#while True:
#action, _states = model.predict(obs)
#obs, rewards, dones, info = e.step(action)
#time.sleep(.5)
#if not render.fresh():
#break
如此就可以训练并将模型保存。
动作空间简化
原始动作空间为([动作id,x坐标,y坐标]),其中动作有9种:Idle, Attack, Collect, Pickup, Consume, Equip, Synthesize, Discard, Move。当然,在enden-v1下动作空间被包装为[左键/右键,目标的x,目标的y]。在40x40的地图配置中,x有82个取值,y有40个取值。在这么大的离散空间中,采样获得正确动作的概率太小,baseline算法如PPO等很难学到一个有意义的结果。因而需要Wrapper对action进行降维、简化,帮助算法学习一个有意义的结果。
因此在游戏中配置了一种action_wrapper的样例,通过env = ActScale(env)包装后就可以完成动作空间的映射。
为了达成合成IronIngot的目标,将动作空间修改如下,
| 原始动作 | 修改方式 | 描述 |
|---|---|---|
| Idle | 删除。 | 在合成环境中没有意义的动作 |
| Move | 不单独进行move,而是其他动作失败后,往目标移动/无目标随机往一个位置移动 | |
| Attack/collect/pickup | 合并后分解为找Apple,找Water,找Wood,找stone,找IronIngot。若有目标在附近且对应产品没有达到最大容量,则move到附近,优先级pickup>attack>equip>collect;否则随机移动。 | 目的类似,获得特定材料 |
| equip | 不独立设置一个编号,嵌入到其他动作中,为了完成目的去装备 | |
| Consume | 分为吃苹果和吃水。没有吃的去做找Apple/Water任务 | - |
| Synthesize/Discard | 不独立设置一个编号,嵌入到其他动作中,为了完成目的去合成装备。Discard在有更高级装备时,可以丢弃低级装备,但目前没有用到 | 智能合成 |
具体动作编号设置如下:
| 编号 | 规则 |
|---|---|
| 0(吃苹果) | 判断Hunger是否小于给定值(设定为400):小于,若背包有Apple则consume,否则执行动作找苹果;大于,若背包Apple数小于上限(60),则执行动作找苹果。 |
| 1(吃水) | 判断Thirst是否小于给定值(设定为400):小于,若背包有Water则consume,否则执行动作找水;大于,若背包Water数小于上限(60),则执行动作找Water。 |
| 2(找水) | 判断Water数量是否大于给定值(设定为100):大于,则不执行此动作;小于,判断附近是否有Pool,若能Collect直接Collect,否则向Pool移动。 |
| 3(找苹果) | 如果Apple数量大于于给定值(设定为100),则不执行,否则:a.判断附近是否有能Pickup的Apple,能捡直接捡,否则向目标位置移动;b.若没有装备WoodAxe则去完成找Wood工作;c.若已经装备WoodAxe且能看见AppleTree,能砍AppleTree直接砍,否则向其移动。 |
| 4(找铁) | a.若没有装备StoneSmelter,完成找StoneSmelter;b.若能合成IronIngot直接合成;c .IronOre不够找生铁;d.Stone不够找石头。 |
| 5(找生铁) | a.若视野内有IronOre,则捡/向其移动;b.若已经装备StoneAxe,则去找IronMine砍;c.找石头。 |
| 6(找StoneSmelter) | a.若有能装备但没装备的StoneSmelter,则装备StoneSmelter;b.判断Stone够不够合成,够则合成,不够则去找石头。 |
| 7(找石头) | a.若附近有能捡的Stone,则捡/向其移动;b.若有能装备但没装备的StonePickaxe,则装备;c.若已经装备StonePickaxe,则去找Rock砍;d.若没有StonePickaxe,判断Stone够不够合成,够则合成,不够则去找Rock收集Stone。 |
| 8(找木头) | a.若附近有能捡的Wood,则捡/向Wood移动;b.若有能装备但没装备的WoodAxe,则装备WoodAxe;c.若已经装备WoodAxe,则去找Tree砍;d.若没有木斧,判断Branch够不够合成,够则合成,不够则去找树收集(Collect)Branch。 |
| 默认 | 上面任务没有满足的目标时,按照"能捡Branch捡branch(防止太多不捡挡路),否则随机移动Speed距离"执行操作 |
相较于默认环境,为了简化任务难度,在实验中做了以下修改:
1.agent理应记录pool的储存数目,否则会做无意义的采水动作;为了简便,设置pool的储量为无限;
2.设定初始Hunger和Thirst为500;
3.苹果只能通过击杀苹果树得到,掉落30个苹果。
在这个配置下,测试一直执行4(找铁)动作是可以获得IronIngot的,说明任务并不难,这个action_wrapper可以看作是一种简单的人工策略。
动作设计机制就参考动作3-动作8的联动,优先级捡>获取所需装备/材料>找。需要完成更高级的合成任务时,可按此机制增加动作(如增加找IronSmelter/Steel这些操作)。
结果样例
在简化动作空间上训练出的一个结果图如下,

可见,智能体可以完成采集树枝、合成/装备木斧、砍苹果树、收集苹果这些操作。实际训练时发现,设置一个合适的reward是能否训练出优秀策略的关键:把生存类的reward调高时(如吃苹果),训练出的模型就只会去吃水/吃苹果,虽然一直死不了,但也不会合成东西;把合成类的reward调高时(如合成铁的reward),训练出的模型就会不顾死活,一直去合成。因此,目前利用PPO训练出的模型很难在生存和合成之间找到一个平衡。